How to Fine-Tune an LLM: Real Costs and When It's Worth It
A practical, cost-first guide to fine-tuning a large language model: what the GPU hours actually cost, the methods that matter, and when to.

How to Fine-Tune an LLM: Real Costs and When It's Worth It

Most teams reach for fine-tuning too early. They've got a base model that keeps hallucinating the wrong format, so they assume retraining is the fix. It isn't, not usually. Before you spend a weekend wiring up LoRA adapters and renting an A100 80GB at $1.64 per hour on RunPod1, you should know exactly what fine-tuning changes, what it doesn't, and when QLoRA on a single GPU is genuinely the right call versus when you're about to pay for a solution to a problem you don't actually have.
This article covers the four main methods, the real VRAM numbers, the 2026 managed API prices, and a decision framework. Numbers are time-stamped to mid-2026 because GPU rental markets move fast.
What Fine-Tuning Actually Does (and What It Doesn't)
Fine-tuning is not a knowledge injection tool. That's the mistake most teams make. You can't fine-tune a model to "know" your company's Q3 earnings and expect it to answer questions about Q4. The weights bake in patterns, not facts.
- Fine-tuning
- Continued training on a curated dataset that updates a model's weights so it adopts a specific style, output format, or domain reasoning pattern. It does not add retrievable facts.
- Pre-training
- The original large-scale training run that builds the model's world knowledge. Fine-tuning happens after this, on a fraction of the data, at a fraction of the cost.
Fine-tuning is most cost-justified when the task needs consistent output format, style, or domain reasoning that prompting and RAG cannot reliably produce.2 Think: a model that always emits structured JSON with a specific schema, or one that answers in the clinical register of a medical summarizer.
What fine-tuning doesn't do:
- It doesn't give the model access to data it wasn't shown at training time.
- It doesn't fix reasoning failures that stem from the base model's architecture limits.
- It doesn't replace a retrieval layer for facts that change weekly.
The shortest summary: fine-tuning teaches the model how to respond. RAG teaches it what to respond about. They solve different problems, and conflating the two is the fastest way to waste a training budget.
The Four Methods: Full Fine-Tuning, LoRA, QLoRA, and Managed APIs
Four approaches, meaningfully different resource profiles.
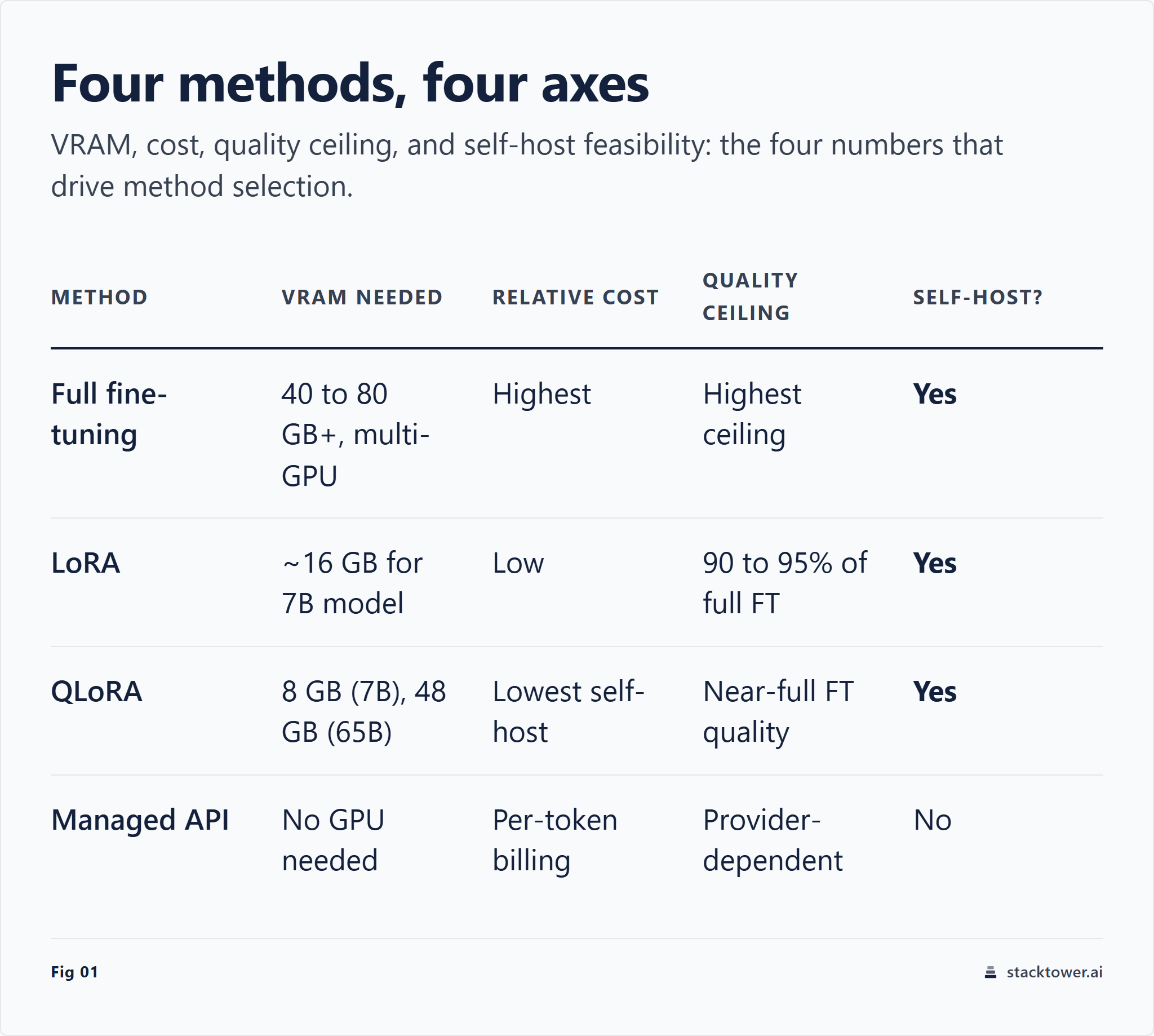
Full fine-tuning updates every weight in the model. Highest quality ceiling, highest cost. You're paying for that ceiling whether you need it or not.
LoRA (Low-Rank Adaptation) freezes the base weights and trains small rank-decomposition matrices inserted into the attention layers. LoRA fine-tunes a 7B model using a fraction of the VRAM of full fine-tuning by decomposing weight updates into low-rank matrices.3 In practice, LoRA trains only about 0.1 to 1 percent of parameters and recovers roughly 90 to 95 percent of full fine-tuning quality at far lower memory cost.
QLoRA goes further. QLoRA further reduces VRAM by quantizing the base model to 4-bit, enabling 65B-parameter models to fine-tune on a single 48GB GPU.4 The mechanism is 4-bit NormalFloat (NF4) quantization with no meaningful performance loss versus 16-bit full fine-tuning, per Dettmers et al. 2023. QLoRA cuts base-model VRAM 40 to 70 percent compared to LoRA, with roughly 0.8 to 0.9x training speed due to dequantization overhead.
Managed APIs (OpenAI, Vertex AI, Together AI) abstract away all of this. You pay per token, not per GPU-hour. The tradeoff: you're locked to a provider's model family, you can't run the weights yourself, and the per-token costs compound fast at scale.
LoRA hyperparameters worth knowing:
- Rank (r)
- Controls the size of the adapter matrices. r=8 for simple tasks, r=16 as a default, r=32 to 64 for complex domains. Higher rank means more trainable parameters and more VRAM.
- Alpha
- Scaling factor for the LoRA updates. Commonly set equal to rank, or 2x rank. A higher alpha amplifies adapter influence on the output.
- Target modules
- Which attention projections to adapt. Most practitioners target q_proj and v_proj as a starting point.
VRAM Requirements by Method and Model Size
The numbers are the story.
Full fine-tuning a 7B model needs at least 40 to 80GB VRAM and typically multiple high-end GPUs5 because you're holding the full model in 16-bit precision plus optimizer states and gradients. That is not an A100 40GB job. That is a multi-GPU job.
LoRA and QLoRA change the picture substantially:
- A 7B model with LoRA fits in roughly 16GB VRAM at sequence lengths up to 2048 tokens.
- A 7B model with QLoRA fits in as little as 8GB VRAM, viable on an RTX 4060.
- A 65B model with QLoRA fine-tunes on a single 48GB GPU, an A6000 or an A100 40GB slot.
IMHO the 7B QLoRA path is the correct default for most practitioners who don't have a research budget. You get near-full-fine-tuning quality, you can run it on a rented consumer GPU, and you're done in hours, not days.
GPU Rental Costs in 2026: RunPod, Vast.ai, and Lambda
These prices are mid-2026 spot rates. They'll drift. Use them as order-of-magnitude anchors, not invoice previews.
A100 80GB SXM on-demand rates:1
| Platform | Price per hour |
|---|---|
| Vast.ai (on-demand) | $0.67 to $1.89 |
| RunPod Community | $1.64 |
| RunPod Secure | $2.21 |
| Lambda | $2.49 |
Vast.ai spot pricing for an A100 80GB PCIe can drop as low as $0.13 to $1.20 per hour depending on availability, per runaihome.com's 2026 pricing comparison.
H100 80GB SXM rates have fallen roughly 40 percent from early 2025, landing around $1.00 to $2.13 per hour on Vast.ai spot, $1.99 per hour on RunPod Community, and $3.29 to $4.29 per hour on Lambda as of mid-2026.
A practical QLoRA fine-tuning run on a 7B model typically takes 2 to 8 hours on an A100 80GB depending on dataset size and sequence length. At RunPod Community rates, that is roughly $3.28 to $13.12 total for the GPU compute alone. Data prep, storage, and your time are not in that number.

Managed Fine-Tuning Pricing: OpenAI, Vertex AI, and the Per-Token Math
This is the load-bearing section. Get the math wrong here and you'll over-build.
OpenAI fine-tuning is billed per training token and per inference token on the fine-tuned model.6 The GPT-4o tier runs approximately $25 per 1M training tokens; the mini tier drops to approximately $3 per 1M training tokens. There is a critical caveat that does not appear on most comparison pages: OpenAI is winding down its fine-tuning platform and is no longer accessible to new users. Existing users can continue training for a limited time, and fine-tuned models stay usable for inference until the base model is deprecated. If you're evaluating this for a new project in 2026, OpenAI's fine-tuning platform is not a realistic path.
Hosting costs add up separately. A fine-tuned model hosted on an OpenAI-style dedicated endpoint can cost $1.70 to $3.00 per hour regardless of actual usage. Monthly that runs roughly $1,224 to $2,160 depending on the rate. Low query volume makes this agonizing.
Google Vertex AI (Gemini) bills fine-tuning at approximately $3.00 per 1M training tokens.7 From Gemini 3 onward, the tuned endpoint prediction price is 1.5x the base inference rate. Older Gemini model fine-tunes bill at the same rate as the base.
Together AI offers open-source 7B training at approximately $0.48 per 1M tokens, which is currently the cheapest managed path for open-weight models.
The per-token math for a typical 7B supervised fine-tuning run:
- Assume 50,000 training examples at an average of 512 tokens each, which is 25.6M training tokens.
- At Together AI rates ($0.48 per 1M), training cost is approximately $12.29.
- At Vertex AI rates ($3.00 per 1M), training cost is approximately $76.80.
- At OpenAI GPT-4o rates ($25 per 1M), training cost is approximately $640.

Training token cost is not the dominant cost. The real budget goes to data labeling, dataset curation, evaluation, and the ongoing inference hosting. In my experience the surrounding pipeline (data prep, labeling, evaluation, monitoring) costs 5 to 10x the raw training compute.
When Fine-Tuning Beats RAG, and When It Doesn't

RAG outperforms fine-tuning for up-to-date or frequently changing knowledge, because fine-tuning bakes knowledge into weights at training time.8 If your facts change weekly, re-indexing a vector store is cheap. Retraining is not. RAG also gives you citable, auditable outputs, so you can trace which retrieved chunk produced a given answer. Fine-tuning gives you none of that.
Fine-tuning wins in a narrower set of cases. Here's the honest split.
Use fine-tuning when:
- The output format is highly structured (JSON schema, specific templates) and prompt engineering keeps drifting.
- The domain reasoning pattern is stable and unlikely to change, like medical coding, legal clause extraction, or financial instrument classification.
- Query volume is high enough to amortize upfront training cost through lower per-query inference latency and cost.
Use RAG when:
- Facts change faster than you can retrain, like product catalogs, news, or support knowledge bases.
- You need auditability, the ability to cite which source produced a given answer.
- You're still exploring the task. RAG lets you iterate on your knowledge base without touching model weights.
To go deeper on what retrieval actually does, understanding how RAG works at the architecture level will sharpen your intuition for where the two approaches diverge.
Most serious production systems in 2026 use both. Fine-tuning establishes the model's behavioral register; RAG fills in the facts at inference time. The decision isn't binary. It's a sequencing question. See the full RAG vs fine-tuning comparison for the cost breakdown side by side.
The Honest Verdict: A Decision Framework
Fine-tuning is worth the upfront cost under specific conditions. It's a waste under others. Here's the framework:
- Is the knowledge stable? If facts change monthly or faster, RAG wins. Don't retrain to inject knowledge.
- Is the output format or style the problem? If prompting can't reliably produce the format you need, LoRA or QLoRA is the right tool.
- Do you have clean labeled data? You need at least 500 to 1,000 high-quality examples for a fine-tuning run to move the needle. If you don't have them, stop here.
- What is the query volume? Low volume means the hosting cost never amortizes. High volume can make a fine-tuned open-weight model significantly cheaper per query than a frontier API.
- Can you run open-weight models? If yes, QLoRA on a rented A100 at $1.64 per hour is a legitimate path. If no, Vertex AI at $3.00 per 1M training tokens is the most accessible managed option in 2026.
In my experience, the teams that benefit most from fine-tuning have three things in common: a stable task definition, a real dataset they own, and query volume high enough to care about per-inference cost. If you're missing any one of those, RAG plus a well-engineered prompt will serve you better and ship faster.
For practitioners building toward this skill set professionally, the AI engineering career path in 2026 covers where fine-tuning proficiency sits in the broader skill stack employers are actually hiring for.
Everything in this article can be stress-tested in roughly an afternoon. The Hugging Face PEFT quicktour is a runnable QLoRA notebook that will show you actual VRAM consumption and training speed on a 7B model. Load it, run it with your own data, and compare what you observe against the VRAM numbers above. If your numbers disagree with mine, the digest sources are linked, so check the primary evidence before concluding either of us is wrong.
Footnotes
-
runaihome.com GPU cloud pricing comparison, mid-2026 snapshot. https://runaihome.com/blog/cloud-gpu-pricing-runpod-vast-lambda-2026 ↩ ↩2
-
AICost.ai, "RAG vs Fine-Tuning cost and use-case guide". https://aicost.ai/ai-cost-guides/calc/rag-vs-fine-tuning ↩
-
Hugging Face PEFT documentation, LoRA method overview. https://huggingface.co/docs/peft/main/quicktour ↩
-
Dettmers et al. (2023), "QLoRA: Efficient Finetuning of Quantized LLMs". https://arxiv.org/abs/2305.14314 ↩
-
NVIDIA NeMo Framework documentation, SFT and PEFT/QLoRA VRAM requirements. https://docs.nvidia.com/nemo-framework/user-guide/24.07/sft_peft/qlora.html ↩
-
OpenAI fine-tuning platform wind-down notice, announced 2026-05-08. https://developers.openai.com/api/docs/deprecations ↩
-
Google Cloud Vertex AI Gemini fine-tuning pricing, cloud.google.com. https://cloud.google.com/gemini-enterprise-agent-platform/generative-ai/pricing ↩
-
FutureAGI, "RAG vs Fine-Tuning Decision Framework 2026". https://futureagi.com/blog/rag-vs-fine-tuning-decision-framework-2026 ↩