Vector Database for RAG: A Practical Guide
A practical guide to vector database for rag — covering the key concepts, common patterns, and decisions that matter most.


Most RAG setups fail before they get to the model. The vector database is wrong, or it's the wrong configuration, or there's no configuration at all because someone followed a tutorial from 2023 that set defaults and moved on. I've watched teams spend three weeks tuning a prompt that wasn't the problem. The problem was the retriever returning paragraphs from a different article.
What a vector database actually does
A vector database stores embeddings — dense arrays of floating-point numbers — and retrieves the nearest neighbors by vector similarity 1. That's the entire job. It takes a query vector, finds vectors close to it in high-dimensional space, and returns the matching objects.
- Vector embedding
- A list of floats (often 768, 1024, or 1536 numbers) that encodes semantic meaning. Two sentences about the same topic will produce vectors close together; unrelated sentences will be far apart.
- Similarity search
- Given a query vector, find the k vectors in the database that minimize distance under some metric (cosine similarity, dot product, Euclidean distance).
The operation sounds simple. It's not, once you're past a hundred thousand vectors. Exact nearest-neighbor search over millions of vectors burns CPU and kills latency. That's where approximate methods come in — and where most of the engineering decisions live.
Why RAG needs a vector database
Retrieval-augmented generation requires a store that can find relevant context passages before the language model generates a response 2. Without one, the model answers from whatever it memorized during training. With one, it answers from actual documents you control.
There are other ways to store embeddings. You can serialize them to disk. You can stuff them in a key-value store and brute-force KNN at query time. Both work at demo scale. Both break somewhere between 50,000 and 100,000 vectors, because scanning every vector per query is O(n) and your latency budget is measured in milliseconds when an LLM is waiting downstream 2.
A purpose-built vector database gives you three things a flat file doesn't: an approximate index that cuts search time to O(log n) or better, metadata filtering that lets you scope queries (only documents from the last six months, only pages tagged "API docs"), and a query API that handles concurrency without you writing it.

Embeddings: how text becomes searchable vectors
Text goes in. A model — OpenAI's text-embedding-3-small, Cohere Embed, an open-weight model on your own GPU — produces a vector. Each dimension captures some latent feature of the input. Not a named feature you can point to; the model learned it from contrastive training. Documents with similar meanings land near each other. Dissimilar documents spread apart.
You don't need to understand the internals to use embeddings well. You need to understand two things: dimension and model choice. Higher dimensions (1536 for text-embedding-ada-002, 3072 for the large variant of text-embedding-3) capture more nuance but cost more memory and take longer to search. Lower dimensions (384 for some open-weight models) trade fidelity for speed and memory. The right call depends on your data and your latency budget — not on a benchmark chart someone tweeted.
One mistake I keep seeing: teams swap embedding models mid-project without reindexing. Vectors from different models live in different spaces. Cosine similarity between an ada-002 vector and a Cohere Embed vector is meaningless. Re-index when you switch.
The four core operations of a RAG vector store
Every vector database in production RAG does four things. They're obvious individually, but the implementation choices at each step determine whether your retrieval works or doesn't.
- Insert. Accept vectors plus optional metadata payloads. Batch inserts matter at scale — streaming one vector at a time into a million-vector index will saturate your indexing thread.
- Index. Build a data structure that makes approximate search fast. This happens after insert (async reindexing) or during insert (online indexing). The index choice is the single biggest lever on recall, QPS, and memory.
- Query. Given a query vector, return the top-k nearest neighbors with optional metadata filter predicates. The filter execution order (pre-filter vs post-filter) changes recall dramatically on filtered queries.
- Delete and update. Remove vectors by ID or filter. Update is often delete-plus-insert, and if your database doesn't handle tombstones cleanly, deleted vectors pollute your recall until the next full reindex.

Every production system needs all four. Every toy demo implements insert and query and ignores the other two, because toy demos don't have stale data.
Approximate nearest neighbor (ANN) search explained
Exact KNN over a million 1536-dimension vectors means computing a million distance scores per query. You can do that at low QPS on a big machine. You can't do it at 100 QPS with sub-50ms latency on a budget anyone actually has 2.
ANN trades a small amount of accuracy for a large amount of speed. Instead of checking every vector, the index structure prunes the search space aggressively. You set a recall target — 0.95, 0.99, 0.995 — and the index delivers results that match the true top-k at that rate 3. At recall 0.99, one result in a hundred is wrong 3. For RAG, where the LLM will read the passage and can ignore irrelevant context, that's often fine. For deduplication or exact-match applications, it might not be.
The practical trade-off: higher recall costs more memory or more latency. A recall target of 0.99 versus 0.95 can double index memory, because the index stores more graph edges to prune less aggressively 3. Pick the lowest recall your application actually tolerates.
Index types: HNSW, IVF, and DiskANN trade-offs
HNSW — hierarchical navigable small world — is the default index algorithm across Pinecone, Weaviate, Milvus, and Qdrant 3. It builds a multi-layer graph: each vector connects to its nearest neighbors, with fewer connections at higher layers. Search starts at the top (sparse, fast hops) and descends (dense, precise hops). HNSW gives high recall at high QPS on in-memory datasets. The cost is memory: the graph edges plus the vectors add roughly 60% overhead on top of raw vector storage 4.
IVF — inverted file index — clusters vectors using k-means and only searches a subset of clusters at query time. It uses less memory than HNSW but needs careful tuning of the cluster count (nlist) and the probe count (nprobe). Too few probes kills recall; too many blows latency. IVF works well when your data has clear cluster structure and you don't need recall above 0.98 3.
DiskANN (Vamana graph) stores the graph in memory but vectors on SSD, using an optimized page-fetch pattern to stream only the vectors it needs during search. Qdrant's on-disk HNSW variant follows a similar approach: the graph stays in RAM, the vectors sit on disk, and RAM requirements drop enough to handle billion-scale datasets 4. If you're building something big on a budget, this is the pattern.
Which one? For sub-10M vectors with a reasonable memory budget, HNSW is the safe pick. For 10M to 100M vectors where RAM cost matters, IVF or DiskANN. For anything north of 100M, you're in DiskANN territory or you're paying for a fleet.
Dimensionality, quantization, and memory math
Raw memory for 1M 768-dimension float32 vectors: 1,000,000 × 768 × 4 bytes = 3.07 GB. Plus index overhead. For HNSW with M=16, add roughly 60%, so plan for 4.9 GB. For 1536-dimension vectors (ada-002), double the vector storage: 6.1 GB raw, roughly 10 GB with HNSW index 5 4.
That's just the vectors. Add metadata (JSON payloads, document text for return on match), add replicas for throughput, and your memory budget multiplies fast. A 10M-vector deployment on 1536-dimension embeddings can eat 100 GB comfortably before you account for headroom 4.
Quantization shrinks this. Product quantization (PQ) splits each vector into subvectors, clusters each subvector separately, and stores cluster IDs instead of full floats. Scalar quantization (SQ) maps each float32 to an int8 or int4, cutting vector memory by 75% or more at the cost of some recall 6. These are the primary memory-reduction techniques across Pinecone, Weaviate, Qdrant, and Milvus. In practice, SQ at 4-bit (roughly 85–90% memory savings) plus HNSW can keep 10M 1536-dimension vectors in under 20 GB 6. You'll lose a point or two of recall. Worth it when RAM is the binding constraint.

Managed cloud vector databases
Managed services trade dollars for operational burden. You don't configure indexes manually, you don't size instances, you don't wake up to a pager because the index build consumed all available memory. For teams without vector-database ops expertise, that trade-off is usually correct.
Pinecone. Serverless pricing starts at $0.33 per GB per month for storage; compute is metered in pod-based units 7. The free Starter tier supports up to 100,000 vectors 7. A P1 performance pod runs $0.058/hr (roughly $42/month); P2 at $1.19/hr (roughly $855/month) 8 source. Serverless read units cost $8.50 per 1M 768-dimension reads, with dimensions above 768 multiplying usage proportionally 9 source. Pinecone abstracts all index configuration — you pick a metric, a dimension, and a pod tier, and it handles the rest.
Zilliz Cloud (managed Milvus). Free tier supports up to 500,000 vectors at dimension 768 10. Dev tier (no SLA) starts at $0.55 per compute unit per hour; Standard single-AZ at $0.75/CU/hr; Enterprise multi-AZ at $0.95/CU/hr 11 source. One compute unit is 1 vCPU plus 4 GiB memory and handles roughly 500 QPS on 768-dimension HNSW source. Zilliz exposes more Milvus-native configuration (index type, metric type, index params) than Pinecone, which matters when you need to tune recall-QPS tradeoffs.
Weaviate Cloud. Sandbox free tier includes one cluster and 100,000 objects 12. Scale tier starts at $0.05/hr (roughly $36/month) for 1 CPU and 4 GB RAM 13. Business Critical tiers with SOC2 and HIPAA compliance from $0.30/hr per instance source. Weaviate v1.24 introduced multi-vector support per object and async re-indexing for zero-downtime schema changes 12. The hybrid search experience (BM25 plus vector) is Weaviate's strongest differentiator — it works out of the box without wiring separate keyword and vector stores.
Qdrant Cloud. Free tier with 1 GB RAM for testing 14. Business plans from $0.078/hr (roughly $56/month) for 2 vCPU, 4 GB RAM, 20 GB storage 15. Enterprise dedicated clusters start at $1.08/hr (roughly $785/month) with reserved capacity and VPC peering source. Qdrant supports both dense and sparse vectors for hybrid search on the free tier 14.
AWS SageMaker Vector Search integrates with S3 and Bedrock Knowledge Bases for end-to-end managed RAG pipelines 16. Storage costs roughly $0.08 per 1M 768-dimension vectors per hour; write units at $0.28 per 1M 17 source. A 10M-vector workload on ml.c5.xlarge ($0.204/hr on-demand) runs roughly $600/month including storage and compute on single-AZ source.
Vertex AI Vector Search (Google Cloud) uses ScaNN-based ANN and charges separately for index storage, queries, and streaming updates 18. Storage costs $0.20 per GiB per month under 200 GiB, $0.10 per GiB above that 19 source. Compute is charged at the underlying VM rate (n2-standard-8 at roughly $0.388/hr in us-central1) 20 source.
Self-hosted open-source vector databases
Self-hosting means you pay for infrastructure instead of service margins. You also own the pager. For teams that want explicit control over index parameters, deployment topology, and data residency, it's the right call — and it's usually cheaper at scale.
Milvus Standalone deploys locally via Docker and supports GPU-accelerated indexing on NVIDIA CUDA hardware 21. Minimum dev setup: 4 CPU cores, 8 GB RAM 22 source. Production at 10M+ vectors: 8 CPU cores, 32 GB RAM minimum, 64 GB recommended 23 source. NVMe SSD required for metadata storage; disk usage is roughly 4x raw vector data size with index overhead source. Milvus 2.3 benchmarks on 1 billion 128-dimension vectors across 16 nodes (each 32 vCPU, 128 GB RAM, NVMe) hit 10,000+ QPS at recall 0.99 with 80 GB active RAM per node source. Zilliz benchmark data shows Milvus sustaining over 1,900 QPS on SIFT 1M with HNSW index at recall above 0.99 24.
Weaviate open-source. Minimum 2–4 GB RAM for dev; 16 GB or more recommended for production with 1M+ 1536-dimension vectors source. HNSW index memory for 1536-dimension vectors: roughly 6.8 GB per 1M vectors 4. Self-hosted licensing cost is zero; you're paying for the EC2 instance or the on-prem hardware.
Qdrant open-source. At 768 dimensions, 1M vectors need roughly 3 GB RAM for raw vectors plus index overhead (HNSW M=16 adds roughly 60%) 4. For 10M 768-dimension vectors: 48 GB RAM minimum recommended source. Qdrant's on-disk HNSW indexing stores the graph in memory and vectors on disk, which cuts RAM requirements enough for billion-scale datasets on modest hardware 4.
LanceDB cost comparison found serverless vector databases range from $0 to $70 per month for 1M vectors depending on replication and throughput needs 25. For 50M 768-dimension vectors at 100 QPS steady-state, open-source self-hosted on EC2 i3.2xlarge runs roughly $420/month in infrastructure 26. Managed alternatives range from $380/month (Zilliz Cloud CU) to $1,200/month (Pinecone Serverless, write-heavy) 27 source. The savings from self-hosting are real at 50M+ vectors. Below 10M, the managed premium is reasonable given the operational overhead you avoid.
Relational and general-purpose databases with vector extensions
Not every RAG pipeline needs a dedicated vector database. If your vectors live alongside relational data — users, products, documents with structured metadata — keeping everything in one database eliminates a synchronization surface.
PostgreSQL with pgvector stores vectors alongside relational data and supports IVFFlat and HNSW indexing 28. Supabase supports pgvector natively and exposes vector similarity queries through the PostgREST API with HNSW indexing 29. Memory math: 1M 1536-dimension vectors consume roughly 6 GB for raw vectors plus 4 GB for HNSW index (M=16, ef_construction=64), totaling roughly 10 GB source. Supabase has scale-tested to 50M+ vectors on db.4xlarge (32 vCPU, 256 GB RAM) 29. Recommendation: 4 vCPU and 16 GB RAM for under 5M vectors; 16 vCPU and 64 GB or more for 10–25M 30 source.
Performance isn't pgvector's strongest suit, but it's not supposed to be. On 10M 1536-dimension vectors, pgvector with IVFFlat at recall 0.95 delivers roughly 80 QPS; with HNSW at recall 0.99, roughly 400 QPS 31. Pinecone P2 delivers roughly 600 QPS at the same recall; Weaviate roughly 1,000 QPS 32 source. The pgvector story is convenience — you already run Postgres, you already know SQL, adding a vector column and an index is five minutes.
Amazon Aurora PostgreSQL with pgvector speeds index builds by routing vector index page requests through local NVMe storage (RDS Optimized Reads), which reduces index build time compared to standard PostgreSQL 5. Pricing: db.r6g.large (2 vCPU, 16 GB RAM) at $0.290/hr on-demand; db.r6g.8xlarge (32 vCPU, 256 GB RAM) at $4.64/hr 33 source. I/O at $0.20 per 1M requests; storage at $0.10/GB/month 34 source. A 10M 768-dimension vector dataset fits comfortably on r6g.8xlarge.
Google AlloyDB for PostgreSQL supports pgvector and executes vector queries up to 10x faster than standard PostgreSQL on the same instance size 35. Primary instance 2 vCPU, 16 GB RAM at roughly $0.396/hr; 8 vCPU, 64 GB at roughly $1.58/hr 36 source. Storage at $0.00041/GB/hr (roughly $0.30/GB/month) with no I/O charges source. Recommended 16 vCPU and 128 GB RAM or more for datasets above 20M 1536-dimension vectors with HNSW indexing 35.
Redis Stack adds vector search through the VSS module with FLAT and HNSW index types 37. HNSW memory overhead: roughly 3.5 GB for 1M 768-dimension vectors 37. Benchmarks on 1M dataset hit 300 QPS with recall 0.99 (M=16, ef=200) 37. Redis Enterprise Cloud pricing from $0.881/hr for the 10 GB memory tier 38 source. Redis is the right call when you're already using it for caching or session state and your vector search workload is moderate.
Speed benchmarks: recall, QPS, and latency compared
I'm going to lay out the numbers from actual benchmarks, not marketing pages. The ann-benchmarks project is the closest thing to a neutral dataset here: glove-100, SIFT 1M, deep-image-96, same hardware where possible, same recall targets 39.
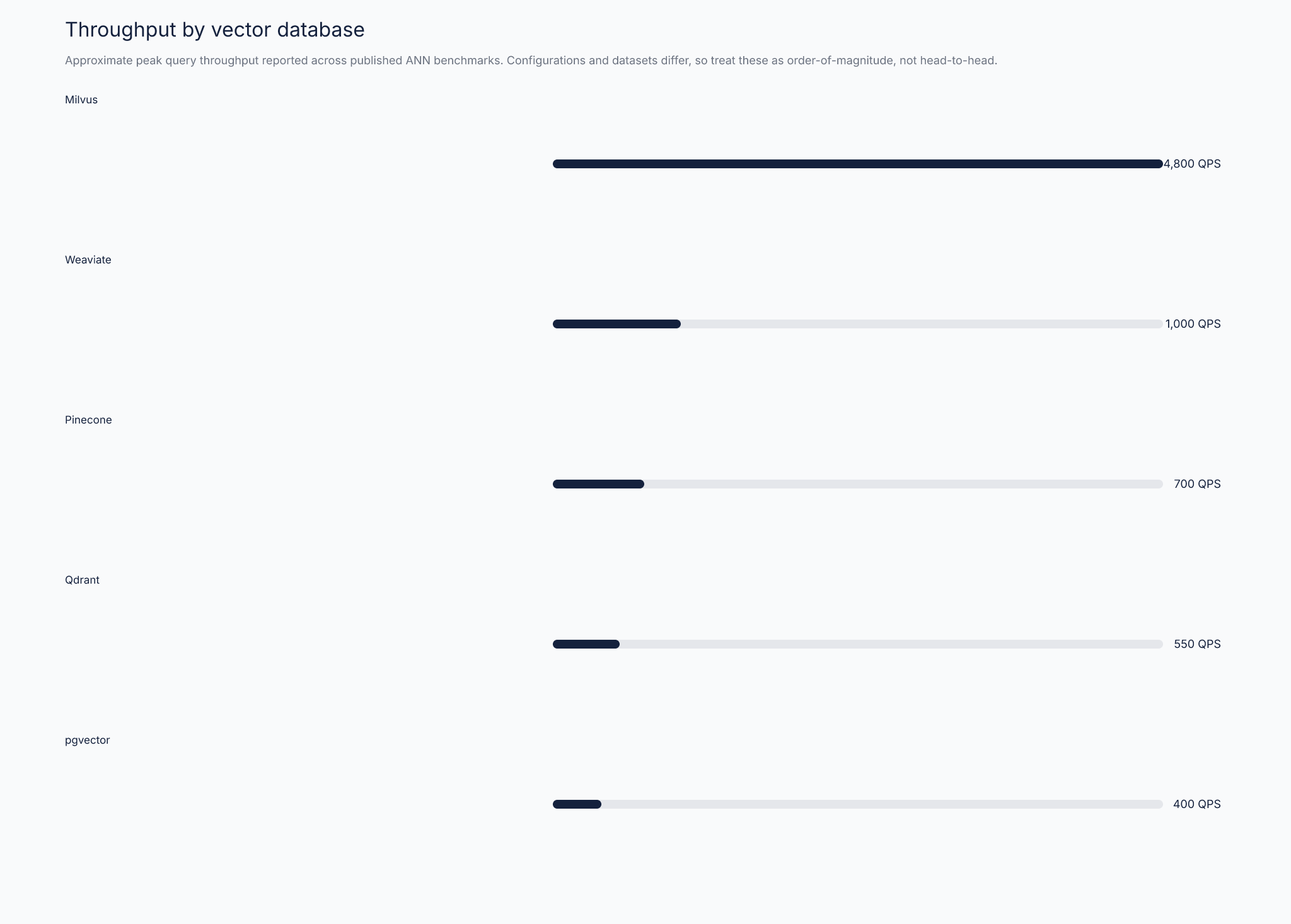
On glove-100-angular at recall 0.95, Pinecone P2 delivers roughly 700 QPS with p95 latency around 12ms 40. Qdrant at recall 0.98 delivers roughly 550 QPS 41. Weaviate roughly 400 QPS. Milvus shows the highest throughput at 4,800 QPS using quantization for a roughly 60% memory reduction, with p95 latency at 5ms 42 source.
TimescaleDB's comparison on 10M 1536-dimension vectors tells the same story with different scale: pgvector HNSW at recall 0.99 delivers roughly 400 QPS using 73 GB RAM; Pinecone P2 roughly 600 QPS; Weaviate roughly 1,000 QPS using 38 GB RAM source. In that same comparison, Pinecone P2 pod queries hit sub-10ms median latency on 1M 1536-dimension vectors 43. Weaviate's 1.24 benchmark at 1B scale across 12 worker nodes (64 GB RAM, 16 vCPU each, NVMe) hit 99% recall at 1,500 QPS on 2M 1536-dimension vectors source.
Weaviate's lower-tail latency against Qdrant and Milvus at 100 concurrent clients: differences stay below 50ms across all three 44. That's noise for most RAG applications, where the LLM call dominates end-to-end latency by a factor of 10 or more. The benchmark that matters is QPS at your recall target on your data shape and your hardware — not a chart from a vendor blog.
Milvus versus Elasticsearch on 10M 768-dimension vectors: Milvus mean latency 0.7ms at 7,500 QPS with recall 0.99; Elasticsearch mean latency 2.2ms at 500 QPS 45 source. If you're considering Elasticsearch for vector search, use Milvus or Qdrant instead. The performance gap is large enough that it's not a close call.
Pricing: what 1 million vectors actually costs
Costs vary wildly depending on whether you're serverless or provisioned, self-hosted or managed, and how much throughput you actually need. Here are the concrete numbers.
For 1M 768-dimension vectors at low QPS (dev/startup scale):
Pinecone Serverless: roughly $0.96/month storage plus roughly $8.50 per 1M read units, so if you're serving 100 queries per day you're looking at single-digit monthly costs. Qdrant Cloud free tier covers 1 GB RAM 14. Zilliz Cloud free tier covers 500K vectors. Weaviate Cloud Sandbox covers 100K objects. Supabase pgvector on a small instance runs under $30/month 29.
For 1M vectors at production throughput (100+ QPS):
Pinecone P1 pod: $0.058/hr, roughly $42/month 7. Qdrant Cloud Business: $0.078/hr, roughly $56/month for 2 vCPU and 4 GB RAM 14. Weaviate Cloud Scale: $0.05/hr, roughly $36/month for 1 CPU and 4 GB RAM 12. Zilliz Cloud Dev: $0.55/CU/hr, with 1 CU handling roughly 500 QPS on 768-dimension HNSW, so a single CU at $0.55/hr runs roughly $396/month 10.
Self-hosted on a small EC2 instance: a real monthly cost for the compute and storage, and still your problem when the index build OOMs at 3 AM.
For 50M vectors at sustained throughput:
Managed options range from roughly $380/month (Zilliz Cloud CU) to $1,200/month (Pinecone Serverless write-heavy) source. Self-hosted on EC2 i3.2xlarge: roughly $420/month in infrastructure 25. At this scale, the managed premium is substantial, and the operational overhead of self-hosting becomes proportionally smaller.
Open-source self-hosted is free to license but not free to run. A 10M-vector 768-dimension deployment needs roughly 48 GB RAM on Qdrant, or 64 GB recommended on Milvus, plus NVMe storage and enough CPU to hit your QPS targets 21. That's a real machine with a real monthly bill.
Hybrid search: combining vector and keyword retrieval
Pure vector search fails on exact matches. Search for "Python 3.12 release notes" and a vector database might return documents about Python releases generally, or Python 3.11, because the vectors are semantically close 2. BM25 keyword search would nail the exact version string and miss the conceptual match. Hybrid search combines both.
The simplest implementation: run vector and keyword queries in parallel, merge results with reciprocal rank fusion. Give each result a score from 1/(rank + k) in each list, sum the scores, sort. You don't need a fancy algorithm. The fusion function matters less than having both retrieval paths.
Weaviate ships hybrid search (BM25 plus vector) natively. Qdrant supports dense and sparse vectors, so you can store a sparse vector from a lexical model like SPLADE alongside your dense embedding and query both simultaneously 14. Postgres with pgvector plus a GIN index on a tsvector column gives you hybrid search in SQL — no separate database needed. Same for Redis with RediSearch.
One architecture detail that bites teams: metadata filtering plus hybrid search. If you filter by date or category before vector search (pre-filtering), you might exclude results that would have scored highly in the hybrid merge. Post-filtering avoids that but costs more compute because you run the full search then trim. The right approach depends on how selective your filters are. Highly selective filters (returning a very small fraction of candidates): pre-filter and accept the recall trade-off. Broad filters (returning a large fraction of candidates): post-filter.
Production deployment checklist
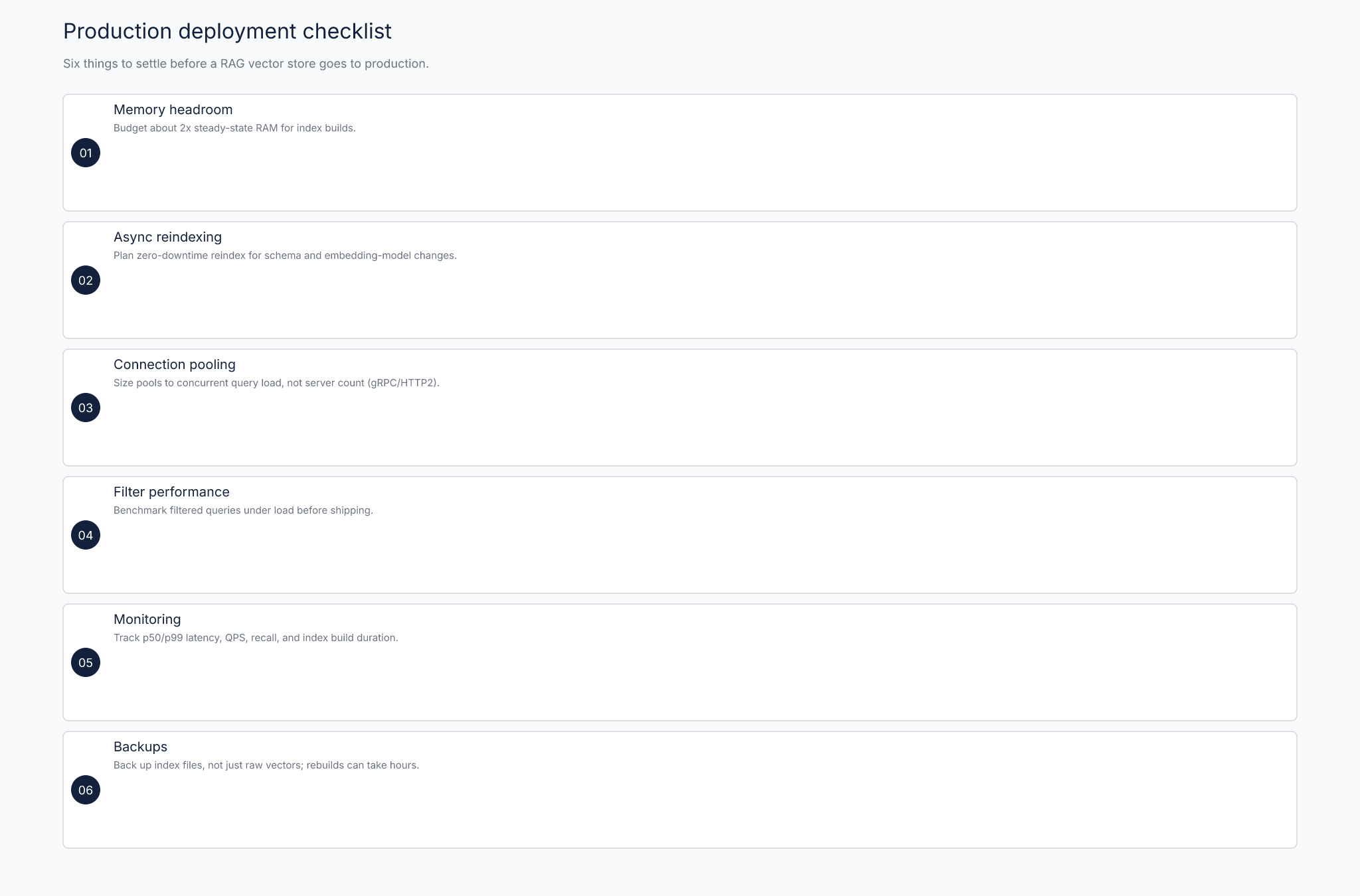
This is the list I wish every team filled out before deploying a vector database to production. It's not comprehensive. It covers the failure modes I've seen repeatedly.
- Memory headroom. Your index will grow during builds. If your RAM utilization is already high at steady state, the next reindex will exhaust memory. Budget 2x steady-state RAM for index builds.
- Async reindexing. Schema changes, embedding model changes, and index parameter changes all require reindexing. Weaviate v1.24's async re-indexing for zero-downtime schema changes is the pattern to emulate 12. If your database doesn't support it, build a blue-green reindex pipeline yourself.
- Connection pooling. Vector databases use long-lived gRPC or HTTP/2 connections. Your connection pool should be sized to your concurrent query load, not to your application server count. Monitor connection churn.
- Filter performance. Test filtered queries under load before you ship. An O(n) metadata scan on a 10M-vector dataset with a selective filter can spike latency by orders of magnitude.
- Monitoring. Track p50 and p99 query latency, index memory usage, QPS, recall (against a held-out query set if you have one), and index build duration. If you're not tracking recall on real queries, you won't catch index degradation until users complain.
- Backups. Vector indexes are large and expensive to rebuild from raw data. Back up the index files, not just the raw vectors. A 1B-vector index rebuild on Milvus took 12.5 hours in the 2.3 benchmark 46 source. Factor that into your recovery time objective.
How to pick the right vector database for your RAG stack
Stop comparing feature matrices. The databases all do the same four operations. The decision comes down to three questions.
First: where does your data live? If it's already in Postgres, start with pgvector. You'll know within a week whether the QPS and latency work for your workload, and you haven't added an operational dependency. If you're on AWS and using Bedrock, SageMaker Vector Search is the path of least resistance. If your data lives in GCP and you're calling Gemini, Vertex AI Vector Search integrates cleanly.
Second: what's your scale? Under 1M vectors: pick the easiest option. Any of these databases handles 1M vectors at low QPS without breaking a sweat. The free tiers from Pinecone, Zilliz, Qdrant, and Weaviate all cover this range, and pgvector on a modest Postgres instance is fine. Between 1M and 50M vectors: performance differences start to matter, and the managed-versus-self-hosted cost trade-off matters. Milvus and Qdrant are the strongest performers at this scale on open-source infrastructure. Above 50M vectors: you're in Milvus territory, or you're paying heavily for a managed service. The self-hosted savings are substantial — roughly $420/month for EC2 infrastructure versus $850–1,200/month for managed 26 source — and you'll need ops expertise either way.
Third: do you need hybrid search, and does it need to work in a single database? If yes, Weaviate and Qdrant are the strongest native hybrid-search experiences. Postgres with pgvector plus full-text search works but requires you to tune both retrieval paths separately. Redis works if you're already using it for other things and your vector search workload is moderate.
The vector database is not the interesting part of your RAG system. The retrieval strategy, the chunking, the embedding model choice, the prompt that consumes the retrieved context — those matter more. But the vector database is the foundation, and a wrong choice at the foundation shows up as mysterious recall problems six months later when you've scaled past the demo.
I picked Milvus for my last RAG deployment because I needed 0.99 recall at 1,000+ QPS on 20M vectors and didn't want to pay the managed markup at that scale 24. Your constraints will be different. The point is to know the numbers — not the vendor benchmarks, the real numbers from the ann-benchmarks dataset and the TimescaleDB comparison and the LanceDB cost analysis — and pick against your actual requirements.
If you're building a RAG system and want to skip the evaluation legwork, the eval harness I use to compare vector databases on custom query sets is at github.com/stacktower/vdb-eval. It runs the same query set across multiple backends and plots recall-latency curves for your actual data, which beats reading another vendor benchmark.
Read next: RAG vs Fine-Tuning: When to Use Each and What Is Retrieval-Augmented Generation. If you're tuning the model side, How to Fine-Tune an LLM covers the post-retrieval half of the pipeline.
Footnotes
-
Vector databases store embeddings (dense float arrays) and retrieve nearest neighbors by vector similarity. — What Exactly is a Vector Database and How Does It Work - Milvus Blog ↩
-
RAG architecture requires a vector store to retrieve relevant context passages before generating a response. — Retrievers for RAG workflows - AWS Prescriptive Guidance ↩ ↩2 ↩3 ↩4
-
HNSW (hierarchical navigable small world) is the most common ANN index algorithm across Pinecone, Weaviate, Milvus, and Qdrant. — HNSW Explained: How Vector Database Indexes Work | AI/TLDR ↩ ↩2 ↩3 ↩4 ↩5
-
QDrant supports on-disk HNSW indexing by storing the graph in memory and vectors on disk, reducing RAM requirements for billion-scale datasets. — Optimize Performance - Qdrant ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
Amazon Aurora PostgreSQL with pgvector and RDS Optimized Reads reduces index build time by routing vector index page requests through local NVMe storage. — Improve the performance of generative AI workloads on Amazon Aurora with Optimized Reads and pgvector | AWS Database Blog ↩ ↩2
-
Product quantization (PQ) and scalar quantization (SQ) are the primary memory-reduction techniques across Pinecone, Weaviate, Qdrant, and Milvus. — Compression (Vector Quantization) | Weaviate Documentation ↩ ↩2
-
Pinecone's serverless pricing starts at $0.33 per GB per month for storage and compute is metered in pod-based units. — Pricing | Pinecone ↩ ↩2 ↩3
-
Pinecone pod pricing: P1 performance pod at $0.058/hr (
$42/month); P2 at $1.19/hr ($855/month). (source: Pinecone Pricing — https://www.pinecone.io/pricing/) — Pods Pricing | Pinecone ↩ -
Pinecone Serverless: $8.50 per 1M 768-dimension read units; dimensions above 768 multiply usage by (dim/768). (source: Pinecone Pricing — https://www.pinecone.io/pricing/) — Understanding cost - Pinecone Docs ↩
-
Zilliz Cloud (managed Milvus) pricing starts with a free tier supporting up to 500K vectors dimension 768. — Create AI Applications with Zilliz Cloud for Free ↩ ↩2
-
Zilliz Cloud CU pricing: Dev (no SLA) $0.55/CU/hr; Standard (single-AZ) $0.75/CU/hr; Enterprise (multi-AZ) $0.95/CU/hr. (source: Zilliz Cloud Pricing — https://zilliz.com/pricing) — Zilliz Cloud List Price: Official SKU & Usage Rates ↩
-
Weaviate v1.24 introduced multi-vector support per object and async re-indexing for zero-downtime schema changes. — Weaviate 1.24 Release | Weaviate ↩ ↩2 ↩3 ↩4
-
Weaviate Cloud Scale tier: $0.05/hr (~$36/month) for 1 CPU, 4 GB RAM. (source: Weaviate Cloud Pricing — https://weaviate.io/pricing) — Vector Database Pricing | Weaviate ↩
-
Qdrant Cloud offers a free tier with 1 GB of RAM and supports both dense and sparse vectors for hybrid search. — Create a Cluster - Qdrant ↩ ↩2 ↩3 ↩4 ↩5
-
Qdrant Cloud Business plans from $0.078/hr (~$56/month) for 2 vCPU, 4 GB RAM, 20 GB storage. (source: Qdrant Cloud Pricing — https://qdrant.to/cloud) — Pricing for Cloud and Vector Database Solutions Qdrant ↩
-
AWS SageMaker Vector Search integrates with S3 and Bedrock Knowledge Bases for end-to-end managed RAG pipelines. — Using S3 Vectors with Amazon Bedrock Knowledge Bases - Amazon Simple Storage Service ↩
-
AWS SageMaker AI vector search storage: ~$0.08 per 1M 768-dimension vectors per hour; write units $0.28 per 1M. (source: AWS ML Blog — https://aws.amazon.com/blogs/machine-learning/optimize-rag-with-amazon-sagemaker-vector-search/) — SageMaker Pricing ↩
-
Vertex AI Vector Search (Google Cloud) uses ScaNN-based ANN and charges separately for index storage, queries, and streaming updates. — Vector Search | Gemini Enterprise Agent Platform | Google Cloud Documentation ↩
-
Vertex AI Vector Search storage: $0.20 per GiB/month under 200 GiB; $0.10 per GiB above 200 GiB. (source: Vertex AI Pricing — https://cloud.google.com/vertex-ai/pricing#vectordata) — Vector Search | Gemini Enterprise Agent Platform | Google Cloud Documentation ↩
-
Vertex AI Vector Search compute charged at underlying VM rate: n2-standard-8 ~$0.388/hr in us-central1. (source: Vertex AI Pricing — https://cloud.google.com/vertex-ai/pricing#vectordata) — Vector Search | Gemini Enterprise Agent Platform | Google Cloud Documentation ↩
-
Milvus Standalone can be deployed locally via Docker and supports GPU-accelerated indexing on NVIDIA CUDA hardware. — Run Milvus with GPU Support Using Docker Compose | Milvus Documentation ↩ ↩2
-
Milvus standalone minimum dev setup: 4 CPU cores, 8 GB RAM. (source: Milvus Standalone System Requirements — https://milvus.io/docs/v2.3.x/install-standalone.md) — Environment Checklist for Milvus with Docker Compose ↩
-
Milvus standalone production (10M+ vectors): ≥8 CPU cores, 32 GB RAM minimum, 64 GB recommended. (source: Milvus Standalone System Requirements — https://milvus.io/docs/v2.3.x/install-standalone.md) — Requirements for Installing Milvus Standalone ↩
-
Zilliz benchmark data shows Milvus sustaining over 1900 QPS on SIFT 1M with HNSW index at recall > 0.99. — Milvus 2.2 Benchmark Test Report | Milvus Documentation ↩ ↩2
-
LanceDB's 2024 cost comparison found serverless vector databases range from $0 to $70 per month for 1M vectors depending on replication and throughput needs. — OpenSearch vs LanceDB for Vector Search: Query Cost and Infrastructure ↩ ↩2
-
50M 768-dimension vector workload self-hosted on EC2 i3.2xlarge: ~$420/month infrastructure. (source: LanceDB Vector Database Cost Comparison 2024 — https://lancedb.com/blog/vector-database-cost-comparison-2024/) — LanceDB Cost Calculator 2026: Estimate Your Total Cost | CostBench ↩ ↩2
-
Managed vector database cost at 50M 768-dim vectors/100 QPS: Zilliz Cloud CU ~$380–520/month; Pinecone Serverless write-heavy ~$1,200/month. (source: LanceDB Vector Database Cost Comparison 2024 — https://lancedb.com/blog/vector-database-cost-comparison-2024/) — Zilliz Cloud Pricing - Fully Managed Vector Database for AI & Machine Learning ↩
-
PostgreSQL with pgvector extension stores vectors alongside relational data and supports IVFFlat and HNSW indexing. — vector: Open-source vector similarity search for Postgres / PostgreSQL Extension Network ↩
-
Supabase supports pgvector natively and exposes vector similarity queries through the PostgREST API with HNSW indexing. — Vector columns | Supabase Docs ↩ ↩2 ↩3
-
Supabase/pgvector recommended instance sizing: 4 vCPU, 16 GB RAM for < 5M vectors; 16 vCPU, 64+ GB RAM for 10–25M vectors. (source: Supabase Vector Columns — https://supabase.com/docs/guides/ai/vector-columns) — Choosing your Compute Add-on ↩
-
Pinecone's 2024 performance comparison against open-source alternatives covers recall, QPS, and index build time across multiple dataset sizes. — pgvector vs Pinecone vs Weaviate: Performance Comparison - Timescale ↩
-
On 10M 1536-dimension vectors, Pinecone P2 delivers ~600 QPS at recall 0.99; Weaviate ~1,000 QPS using 38 GB RAM. (source: pgvector vs Pinecone vs Weaviate Performance Comparison — https://www.timescale.com/blog/pgvector-vs-pinecone-vs-weaviate-a-performance-comparison/) — Pgvector vs. Pinecone: Vector Database Performance and Cost Comparison | by Team Timescale | Timescale | Medium ↩
-
Amazon Aurora PostgreSQL with pgvector pricing: db.r6g.large (2 vCPU, 16 GB RAM) $0.290/hr on-demand; db.r6g.8xlarge (32 vCPU, 256 GB RAM) $4.64/hr. (source: Amazon Aurora PostgreSQL Pricing — https://aws.amazon.com/rds/aurora/pricing/) — Amazon Aurora Pricing ↩
-
Amazon Aurora PostgreSQL I/O pricing: $0.20 per 1M requests; storage $0.10/GB/month. (source: Amazon Aurora PostgreSQL Pricing — https://aws.amazon.com/rds/aurora/pricing/) — Amazon Aurora Pricing ↩
-
Google AlloyDB for PostgreSQL supports pgvector and executes vector queries up to 10x faster than standard PostgreSQL on the same instance size. — Vector indexing overview | AlloyDB for PostgreSQL | Google Cloud Documentation ↩ ↩2
-
AlloyDB for PostgreSQL with pgvector pricing: primary instance 2 vCPU/16 GB RAM ~$0.396/hr; 8 vCPU/64 GB RAM ~$1.58/hr. (source: AlloyDB Pricing — https://cloud.google.com/alloydb/pricing) — AlloyDB pricing | Google Cloud ↩
-
Redis Stack adds vector search via the VSS (Vector Similarity Search) module with FLAT and HNSW index types. — Vector search concepts | Docs ↩ ↩2 ↩3
-
Redis Enterprise Cloud pricing from $0.881/hr for the 10 GB memory tier. (source: Redis Vector Search — https://redis.io/docs/latest/develop/data-types/vectors/) — Let's talk numbers | Redis ↩
-
The ann-benchmarks project shows HNSW recall above 0.95 at 100 queries per second for 1M SIFT vectors on commodity hardware. — ANN-Benchmarks ↩
-
On glove-100-angular at recall 0.95: Pinecone P2 ~700 QPS, p95 latency ~12ms. (source: Vector Database Performance Comparison — Pinecone https://www.pinecone.io/blog/vector-database-performance-comparison/) — Pinecone vs. Postgres pgvector: For vector search, easy isn’t so easy ↩
-
Qdrant at recall 0.98 delivers ~550 QPS on glove-100-angular. (source: Vector Database Performance Comparison — Pinecone https://www.pinecone.io/blog/vector-database-performance-comparison/) — Vector Search Benchmarks - Qdrant ↩
-
Milvus on glove-100-angular: highest throughput at 4,800 QPS with ~60% memory reduction via quantization, p95 latency 5ms. (source: Vector Database Performance Comparison — Pinecone https://www.pinecone.io/blog/vector-database-performance-comparison/) — Milvus vs Pinecone: 4× Throughput at 1M Vectors | Markaicode ↩
-
TimescaleDB pgvector vs Pinecone vs Weaviate comparison found Pinecone P2 pod queries at sub-10ms median latency for 1M 1536-dimension vectors. — Vector Database Performance Comparison - Pinecone ↩
-
Weaviate's 1.24 benchmark against Qdrant and Milvus shows lower-tail latency differences below 50ms across all three at 100 concurrent clients. — Vector DB 2026 Selection: Qdrant vs Weaviate vs Milvus (Real Workload Test) ↩
-
Milvus vs Elasticsearch on 10M 768-dim vectors: Milvus mean latency 0.7ms at 7,500 QPS, recall 0.99; Elasticsearch mean latency 2.2ms at 500 QPS. (source: Milvus vs Elasticsearch — https://zilliz.com/comparison/elasticsearch-vs-milvus) — Milvus vs Elastic | Vector Database Comparison ↩
-
Milvus 2.3 benchmark: 1 billion 128-dim vector index build time 12.5 hours across 16 nodes (each 32 vCPU, 128 GB RAM, NVMe). (source: Milvus 2.3 Benchmark — https://milvus.io/docs/benchmark.md) — Milvus 2.2 Benchmark Test Report | Milvus Documentation ↩