LLM Agents Explained: How They Work and When to Use Them
A practical explainer on how LLM agents work, the tool-call loop, the failure modes, and when to choose an agent over a simpler approach.

LLM Agents Explained: How They Work and When to Use Them

You've probably wired up a chatbot, maybe even added RAG to it, and then hit the moment where a single model call isn't enough. The task needs a web search, then a calculation, then a decision about whether to ask a follow-up question. That's the moment most developers reach for an "agent" and discover they have no clean mental model of what they've just built.
An LLM agent is a program where a language model acts as the reasoning controller: it observes state, decides which action or tool to invoke next, and uses the result to update its plan.1 The model doesn't just respond once and stop. It runs a loop, and that loop is where almost every interesting behavior (and every interesting failure) lives.
Frameworks like LangGraph, AutoGen, and CrewAI all implement variations of the same underlying loop. ReAct (Reason + Act) is the pattern you'll see referenced in papers and documentation constantly. Get that loop clear in your head and the framework differences become implementation details rather than conceptual puzzles.
What follows covers the loop mechanics, the planning patterns, the frameworks worth knowing, and the failure modes worth fearing. By the end you'll know exactly when an agent is the right call and when you're about to burn three days on a tool-orchestration problem a single prompt would have solved.
What Is an LLM Agent?
Most developers first encounter the word "agent" in a marketing context, which means it arrives with zero precision. Let's be specific.
- LLM Agent
- A program that places a language model in a reasoning-and-acting loop: the model observes the current state (a user message, tool output, or memory retrieval), selects an action (call a tool, emit text, ask a clarifying question), and repeats until a stopping condition is met.
- Deterministic Workflow
- A pipeline where the sequence of steps is fixed in code, and the model fills in values or text at each node rather than choosing what happens next.
Anthropic's engineering guidance draws this distinction explicitly and recommends the simplest approach that reliably solves the task.2 That's not hedging. It's a direct warning that agents add real costs (latency, token spend, error propagation) that a two-step pipeline might avoid entirely.
The anti-pattern most people commit is reaching for an agent framework before writing down what decisions the agent actually needs to make autonomously. If you can enumerate those decisions in advance and hard-code the branching logic, you probably don't need an agent. If the set of possible next actions is genuinely unknown until runtime, you probably do.

The Four Components of an Agent System
Lilian Weng's foundational framing identifies four components of an LLM-powered autonomous agent: planning, memory, tool use, and action execution.3 Every framework you'll encounter maps onto these four, even when the naming differs.
- Planning. The model decides what to do next. This includes decomposing a goal into subtasks, ordering those subtasks, and revising the plan when a tool returns something unexpected.
- Memory. Context the agent can read from. Short-term memory is the context window. Long-term memory is a retrieval store the agent queries explicitly.
- Tool use. Structured calls to external systems: search engines, calculators, code interpreters, databases, REST APIs.
- Action execution. The runtime layer that receives the model's tool call, runs it against the real environment, and returns the result.
These four aren't independent. A weak planner will fail even with excellent tools. A planner with no long-term memory will re-learn facts the agent already retrieved three steps ago. Getting the architecture right means treating all four as a system, not as independent modules you can optimize separately.
How the Tool-Call Loop Works
Here's the anti-pattern: treating the tool-call loop as a black box you configure through a framework's YAML and never fully understand. When the agent misbehaves (and it will), that black-box assumption is what makes debugging take hours instead of minutes.
The loop has three steps that repeat:
- The model receives a context message containing the conversation history, the available tool schemas, and any tool results from prior iterations.
- The model emits a structured response: either plain text (the final answer) or a tool call object naming the tool and its arguments.
- The runtime executes the tool call and appends the result to the context as a new message.
The tool-call loop, where the model emits a structured tool call, the runtime executes it, and the result is returned to the model as a new context message, is the mechanism underlying both OpenAI's Agents SDK and Anthropic's tool-use implementation.4

The loop terminates when the model emits a response with no tool call. That's it. Every orchestration strategy (ReAct, chain-of-thought, plan-then-execute) is a prompt-engineering strategy that shapes what the model emits at step 2. The underlying loop is always the same three steps.
Toolformer (Schick et al., 2023) showed that language models can learn to call external APIs by self-supervised fine-tuning on examples where API calls improve prediction quality.5 That finding matters for a practical reason: base models are now trained to expect the tool-call format, so you're working with the grain of the model rather than against it when you use structured tool schemas.
A related pattern: HuggingGPT (Shen et al., 2023) proposed using an LLM as a controller that selects and orchestrates specialized task-specific models to fulfill complex requests.6 The tool-call loop extends naturally to this architecture. Each "tool" is itself a model call rather than an API, and the loop logic stays identical.
Memory: Short-Term, Long-Term, and Reflection
The mistake developers make here is equating "memory" with "context window length." Context window is short-term memory, and it's the only kind most applications use. But for any task that spans more than a few hundred tokens of history, you need a strategy.
- Short-Term Memory
- The current context window. Fast, zero-latency, but bounded by the model's token limit and expensive to fill with irrelevant history.
- Long-Term Memory
- An external vector store or database the agent queries with a retrieval call. Returns relevant chunks rather than the full history. Covered in depth in the guide to retrieval-augmented generation.
- Reflection
- A meta-cognitive step where the agent re-reads its own action history and writes a higher-level summary or lesson to memory, compressing detail while preserving useful generalizations.
The Generative Agents paper (Park et al., 2023) introduced a memory stream and reflection mechanism that allows simulated agents to summarize and retrieve past experience to inform future behavior.7 Their simulation ran 25 agents in a sandbox town for multiple days of simulated time. Without reflection, the agents' behavior degraded as the memory stream grew: too much irrelevant detail crowded out the signal. With reflection, agents formed generalizations ("Klaus likes coffee") that guided future decisions correctly.
The practical takeaway: if your agent runs more than a handful of tool-call iterations, you probably need explicit memory management. That means:
- Deciding what goes into long-term storage after each iteration.
- Deciding what retrieval query to use at the start of each iteration.
- Deciding when to trigger a reflection pass (every N iterations, or when a task boundary is crossed).
None of these decisions are made for you by the framework. You have to instrument them explicitly.
Planning Strategies: ReAct, Chain-of-Thought, and Task Decomposition
The word "planning" in agent systems means something narrower than everyday usage. It means the strategy the model uses to decide what action to take next.
The ReAct paper (Yao et al., 2022) demonstrated that interleaving reasoning traces with action steps improves task performance and interpretability over either alone.8 The pattern is: the model writes a "Thought:" explaining its reasoning, then an "Action:" naming the tool call, then reads the "Observation:" returned from the tool. This trace structure keeps the model's intermediate reasoning visible, which makes debugging far easier than reading an opaque chain of tool calls.
Three planning strategies worth knowing:
- ReAct. Interleaved thought-action-observation. Good default for tool-using agents. The reasoning trace is written directly into the context, so the model sees its own prior reasoning on each loop.
- Chain-of-thought decomposition. The model writes a full plan up front before taking any actions. Useful for tasks where the ordering of steps matters and can be reasoned out in advance. Brittle when the environment returns surprises.
- Plan-then-execute with re-planning. A hybrid: write an initial plan, execute it step by step, but re-evaluate after each observation and revise the remaining plan if needed. More complex to implement but handles uncertainty better.
The choice between these isn't about which is "best." It's about the task structure. A task with a known outcome space suits chain-of-thought. A task where tool results are unpredictable (web search, user input, live API data) suits ReAct or plan-then-execute. Understanding when to use retrieval versus trained-in knowledge is a related decision that shapes which planning strategy fits.
Frameworks for Building Agents
In my experience, you don't need a framework to build an agent. You need the tool-call loop, a way to manage context, and something to execute tool calls. A few hundred lines of Python covers it.
But frameworks exist for good reasons. They handle retry logic, structured output parsing, multi-agent coordination, and observability out of the box. Widely adopted open-source frameworks include LangChain (with LangGraph for stateful multi-agent graphs), LlamaIndex, Microsoft AutoGen, CrewAI, and Microsoft Semantic Kernel.9
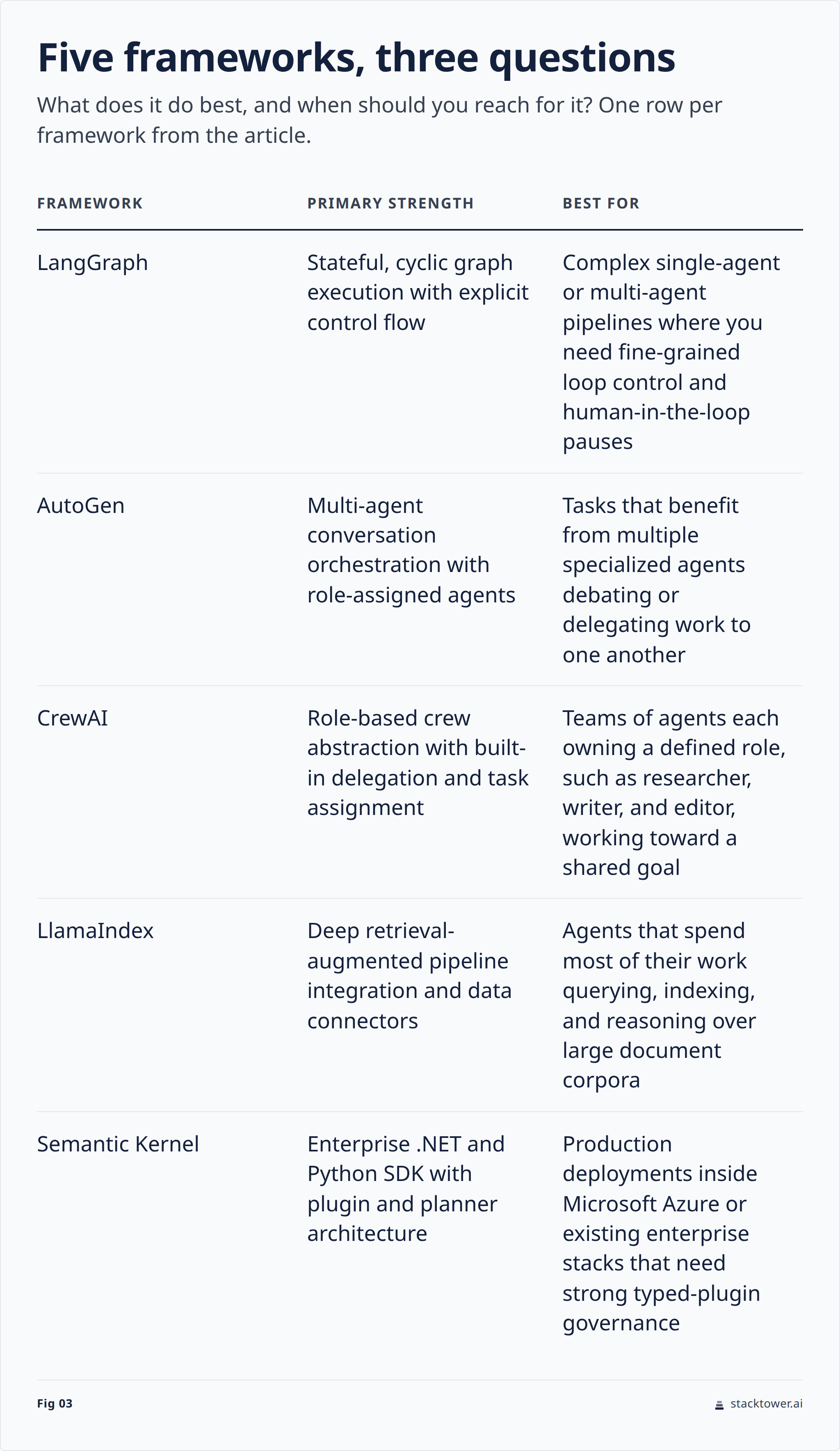
Here's how to choose:
- LangGraph if you want a stateful graph of nodes where you control exactly which transitions fire and under what conditions. Best for complex multi-agent workflows where the topology matters.
- AutoGen if you're building multi-agent conversations where agents send messages to each other and you need a conversation broker.
- CrewAI if you want role-based agent teams with minimal setup and you're prototyping quickly.
- LlamaIndex if your agent is primarily a RAG plus tool-calling pattern and you want tight integration with document ingestion and retrieval.
- Semantic Kernel if you're in a .NET or enterprise Java shop and need a framework that matches that ecosystem.
The framework comparison question is covered in more depth in the guide to becoming an AI engineer in 2026, which includes which frameworks practitioners are actually hiring around.
AgentBench (Liu et al., 2023) evaluated frontier LLMs across eight agent environments and found significant performance gaps between closed proprietary models and open-source models on multi-step decision tasks.10 The gap matters when you're choosing a backbone model, not just a framework. A weaker model inside a sophisticated framework will underperform a strong model inside a minimal scaffold.
Where Agents Break Down: Failure Modes to Know
This is the section most tutorials skip. Every agent demo works. Production agents fail in predictable ways.
A 2024 survey on LLM autonomous agents identifies long-horizon planning and tool hallucination (where the model invokes a tool incorrectly or invents tool capabilities) as the two most persistent open challenges.11 Both are compounding failures: a bad tool call early in a loop produces a bad observation, which corrupts the reasoning trace, which produces another bad tool call.
Four failure modes to test for before you deploy:
- Tool hallucination. The model calls a tool with arguments that don't match the schema, or calls a tool that doesn't exist. Fix: strict schema validation at the runtime layer; return an error message the model can read and recover from.
- Loop termination failure. The model keeps calling tools instead of emitting a final answer. Fix: a hard iteration cap with a forced-stop prompt injected at the cap.
- Context poisoning. A bad tool result early in the loop confuses all subsequent reasoning because the model treats tool outputs as ground truth. Fix: a verification step that sanity-checks tool outputs before appending them.
- Cascading cost. A 10-step agent on GPT-4 class models costs an order of magnitude more than a single-shot call. If the task runs at scale, the cost is not theoretical. Fix: benchmark token spend in staging, not production.
For a detailed look at how fine-tuning can address some tool-use gaps at the model level (rather than the prompt level), see the guide to fine-tuning an LLM.
When to Use an Agent, and When a Simpler Approach Is Enough
Here's the question most teams ask too late, after the agent is already built.
Agents add latency and cost relative to a single model call. For tasks with a clear, bounded decision tree, a deterministic workflow or a single prompted model call is usually faster, cheaper, and more reliable.12 That's not a knock on agents. It's a reminder that the tool-call loop is a mechanism for handling runtime uncertainty, not a universal architecture improvement.
Use an agent when:
- The set of required steps can't be known until the agent sees intermediate results.
- The task requires calling tools in a sequence that depends on prior outputs.
- The task runs in an open-ended environment (web, live data, user input) where the state space is too large to enumerate.
Skip the agent and use a single model call or deterministic pipeline when:
- You can enumerate all the steps in advance.
- The task is a classification, extraction, or summarization with a known output schema.
- Latency matters and the task can be solved in one shot.
- The tool-calling benefit is marginal relative to the orchestration overhead.
The test: write out the decision tree on paper. If it fits on one page with fewer than a dozen nodes, you probably don't need a full agent loop. If it collapses into "and then we see what the tool returns and decide from there," you do.
For context on how this plays out in code-generation tasks specifically, the OpenAI Codex overview for developers walks through a concrete case where the agent pattern is the right call and where a simpler code-completion approach holds up better.
The minimal working implementation is at github.com/stacktower/llm-agent-harness: a single Python file that implements the three-step tool-call loop with no framework dependency, a ReAct prompt template, two toy tools (a calculator and a web search stub), and a configurable iteration cap. Clone it, run it against any OpenAI-compatible endpoint, and you can watch the loop execute step by step. Once you've seen the raw loop working without framework abstraction, the framework choices become much cleaner decisions.